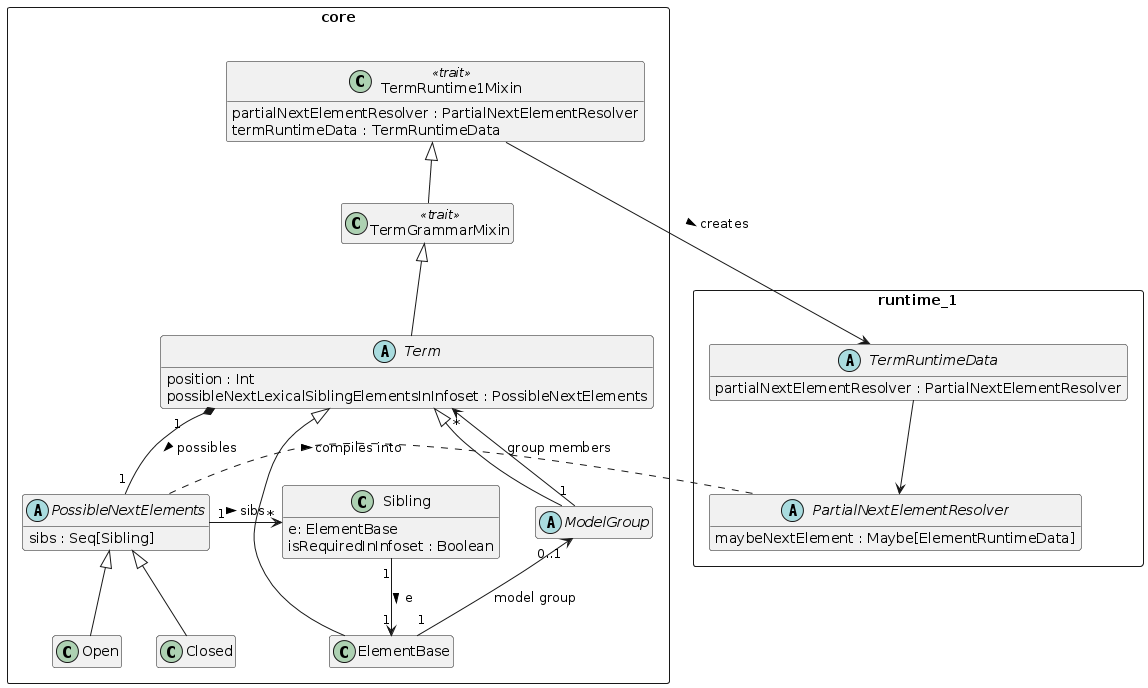
Describes the way the streaming unparser in Runtime 1 works, in particular how the unparser resolves the next element - identifying which ERD (Element Runtime Data) corresponds to the incoming infoset event.
Daffodil Runtime 1 keeps track of the nest of dynamic context terms at runtime on a stack which is maintained by the Unparsers.
At schema compilation time, we compute, for each Term, the set of possible next elements that can follow it, but only as far as the end of the lexically enclosing model group.
This is done in the possibleNextLexicalSiblingElementsInInfoset member of the Term class.
From this information, we compute a element resolver that handles only this partial resolution, which is an instance of class PartialNextElementResolver. This is associated with every Term and carried fro runtime on the TermRuntimeData objects.
This is done in the partialNextElementResolver member of the TermRuntime1Mixin, as the PartialNextElementResolver is a Runtime 1 data structure/object. This object is serialized as part of the TermRuntimeData.
The fact that this is computed using only information going out to the end of the single lexically enclosing model-group avoids a combinatorial explosion in the schema compiler.
At runtime for the Unparser, element resolving is done by the InfosetInputter.
Complete/total element name resolution is done by combining the partial
next element resolvers from the dynamic nest of terms.
This is done with a stack in the UState.
Specifically, the stack, called trdStack is state of the InfosetInputter.
Unparsers are burdened with having to push/pop TermRuntimeData objects to maintain this stack.
The algorithm which iterates down the stack entries to carry out a next element resolution for the InfosetInputter, is carried on the NextElementResolver trait, which is mixed into the InfosetInputter trait, so is shared by all InfosetInputter derived classes. Note that no state is shared. The stack is private to a given instance of an InfosetInputter class, so is private per-thread state just like the rest of the UState.
This design incurs runtime overhead to push/pop TRDs on the stack, and next element resolution is no longer just a single hash-table lookup, but potentially an iteration through multiple such lookups.
Now we focus in on just Term, ModelGroup, and ElementBase. The diagram below shows the Term class, with the possibleNextLexicalSiblingElementsInInfoset member. All Terms have as a member their (1-based) position within the enclosing lexical model group.
The set of possible elements that can follow a given Term can be closed, as when a required element is found downstream. If all downstream elements in the enclosing lexical model group are optional, then the set of possible elements is open ended. The Open/Closed status of the list is signified by a PossibleNextElements case class object correspondingly.
One final detail is that when compiling the set of possible next elements for a choice, there can be elements on branches that are required, but in the context of that choice, if any branch has all optional content, then all the possible next elements for all branches are optional.
The Term itself, if it is an ElementBase, has a isRequiredInInfoset member, which is determined based on properties. When combined in a choice, we need a way to override this, and we encapsulate the ElementBase in a Sibling case class object which carries its own isRequiredInInfoset member which can be set to false to override the underlying ElementBase’s isRequiredInInfoset due to that corresponding element appearing in a choice branch.
The set of possible subsequent ElementBase objects that can follow another is computed inductively starting from the last element or group within a sequence. It is limited to the length of the current sequence, since sequences can be shared.
(Note that unshared i.e., local sequences could in principle be special cased - collapsed together - for purposes of this analysis. We assume here that we will treat all sequence groups as if they were shared via group refs.)
Below we show the runtime 1 objects that implement the next element resolution for the streaming unparser.
The Unparser has a UState, which has an InfosetInputter. The InfosetInputter trait mixes in the implementation of NextElementResolver which provides the push/pop API for maintaining the TRD stack, and it provides the nextElement method which does complete next element resolving, chaining through the PartialNextElementResolvers obtained from the stack of TRDs.
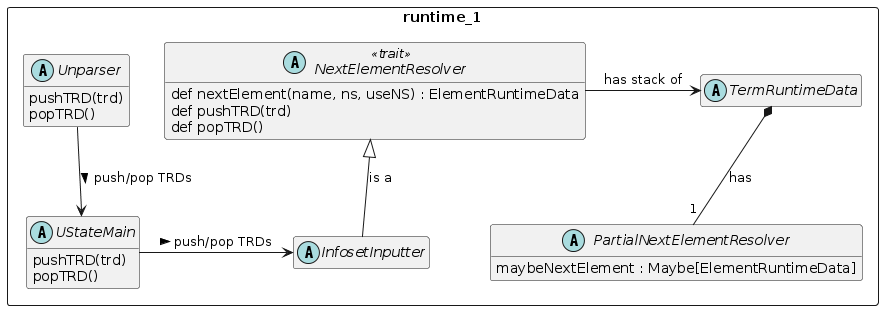
Any given PartialNextElementResolver can resolve a name (+ namespace when used) to an ERD, or it can not be able to perform the resolution, which is not an error.
As a whole the next-element resoluiton algorithm requires that the unparser maintain the stack of TermRuntimeData objects and the resolution algorithm works down the stack using the partial resolver from the most- recently pushed runtime data object first. If that does not resolve the element it either fails - because the partial resolver knows that the incoming element event must be one of the possibilities it represents (Closed set of possibles), or it moves to the next deeper runtime-data object on the stack having a partial next element resolver (for Open set of possibles), and tries that. This continues until it succeeds, or until an ERD is found on the stack, at which point the resolution fails and an unparse error (fatal) is issued.
Note that the context of next-element-resolution cannot span the boundary of a complex element. This is because an end-element event must be received before any subsequent element start events.
This dynamic-context TRD stack need not be copied to UStates for Suspensions as those only occur after Infoset elements have been created.
Orthogonal to suspensions - next element resolution is over before a suspension is constructed for the element.
Next element resolving for the infoset inputter is orthogonal to choiceBranchMap - next element resolution must be done first, and the result of it is used by the choiceBranchMap to choose which branch of the choice is implied by arrival of that element.
Schema Compiler
Unit tests in scala code for schema compiler methods that compute the possibles object. These should cover various combinations of sequences/choices with required and optional elements and groups shared using group references.
Instrumentation in the schema compiler to measure the amount of work going on so that combinatorial explosions are detected earlier. This should output a report of the metrics at the end of compilation, or perhaps incrementally as compilation proceeds.
Runtime 1
Faking TRDs so as to test XML InfosetOutputters in unit testing. Only the partialNextElementResolver member of the TRD is needed. It may be possible to use the schema compiler to create the appropriate scenario of TRDs and ERDs and then the InfosetOutputter push(trd) method can be called to create a stack that matches a test scenario. This allows testing the nextElement resolver algorithm in isolation from the push/pop logic that Unparsers must maintain.
Unparsers must push/pop appropriately. Possibly built in checking can be put in place that detects when a pop is missing? This is TBD as the push/pop may or may not be able to be centralized in the code base.
Dynamic context stack (stack of RuntimeData) in UState
Unparsers maintain dynamic context stack, pushing and popping TRDs as model-groups are processed.
Stack algorithm for NextElementResolver runs down stack trying partial resolutions
Algorithms on Term to determine sets of possibly following infoset events.
In Daffodil, DSOM now enables sharing of ModelGroup members, which are instances of classes derived from Term.
The Term class is central to Daffodil because Terms are the entities that can can resolve scoped properties by combining those from an element ref or group ref, to and element decl or group def, from element decl to type def, etc. Term is the start point for the chains of non-default property providers, and for the chains of default property providers, from which scoped properties are resolved.
For review, a DSOM class diagram showing the Term class hierarchy is below.
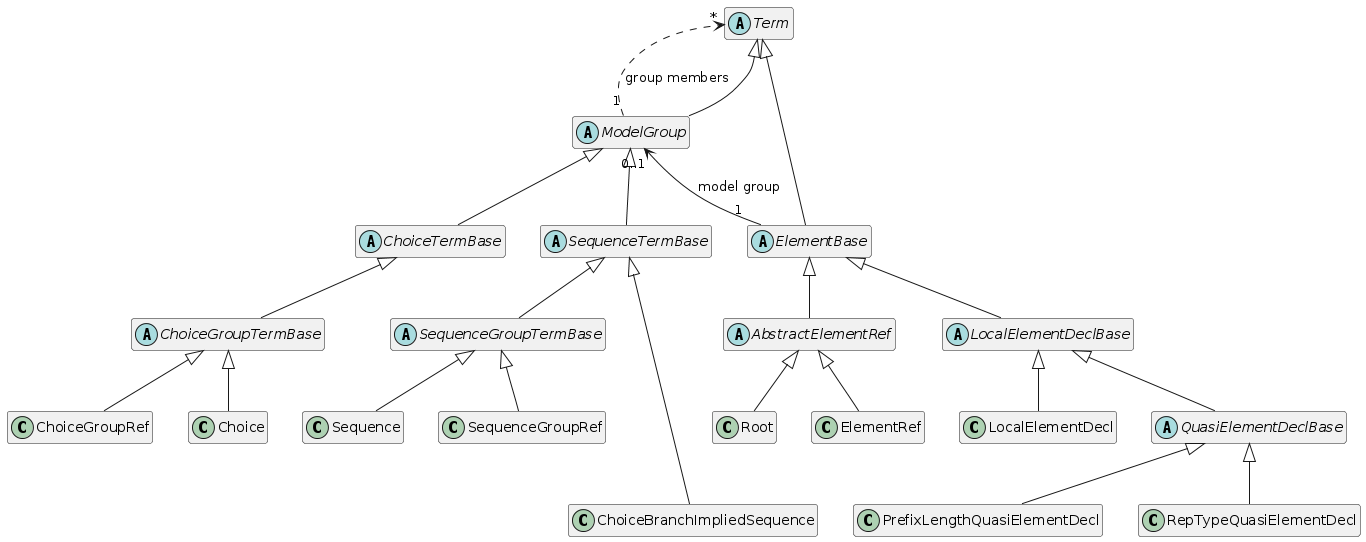
The above reflects the status quo of objects. The concrete classes are all at the bottom (marked with C).
Most of organizing principles depend on just the core abstract classes. Here’s the same diagram, but focusing in on just the core abstract classes.
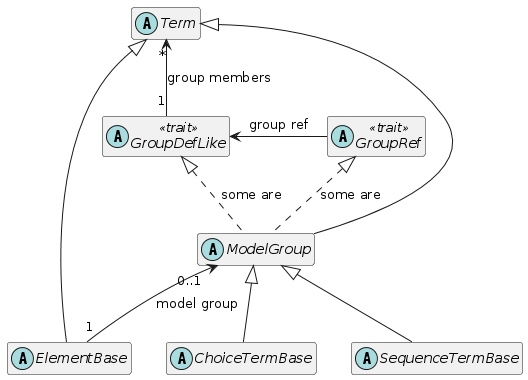
The dashed lines from ModelGroup are to illustrate that some ModelGroup classes inherit from GroupDefLike, as they define lexically, a surround of their group members. Other ModelGroup classes inherit GroupRef (SequenceGroupRef and ChoiceGroupRef) which share the group definition. Ignoring the Root element for a moment, every Term has a lexically enclosing ModelGroup which inherits from GroupDefLike. This is the mechanism by which ModelGroups and their contents can be shared in multiple distinct contexts.
With those classes in mind, we can look into the changes to Daffodil to support a dynamic context stack.
|
|
Some code in the schema compiler has moved around to prepare for an era where Daffodil supports more than one backend/runtime system. See the Appendix: Schema Compiler grammar and runtime1 Packages |
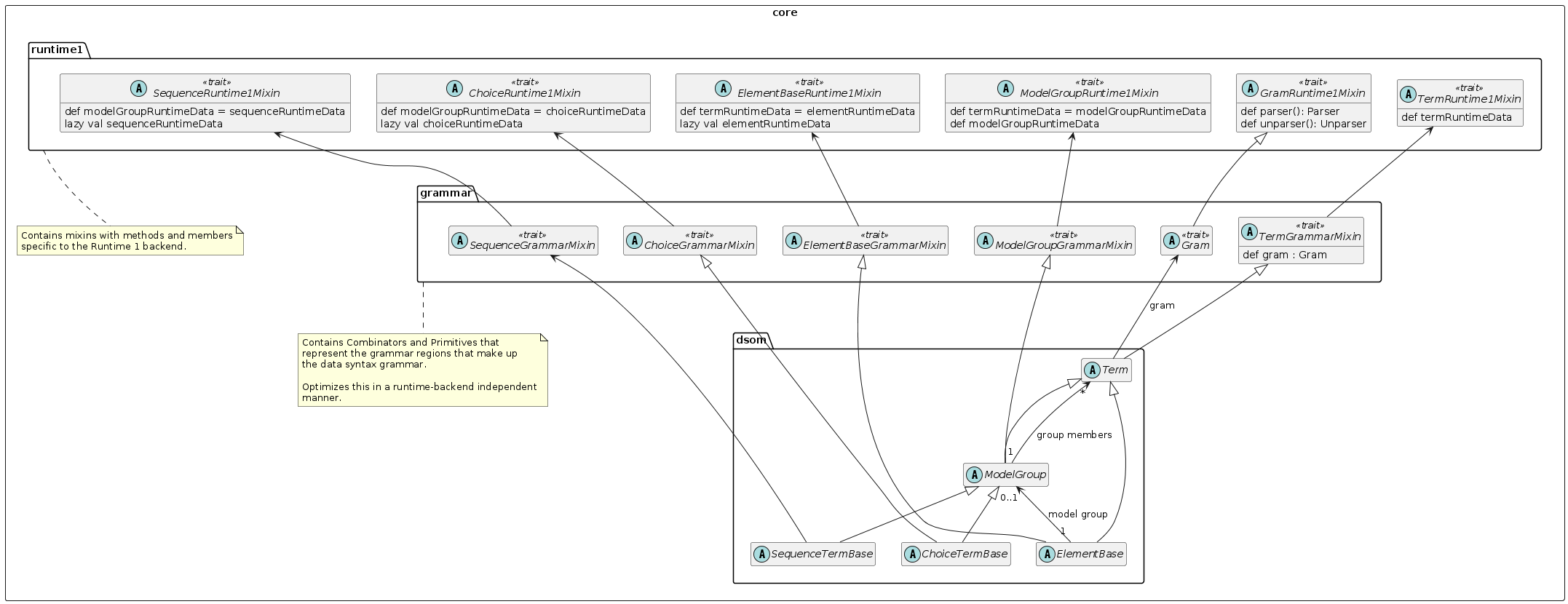
The basic DSOM object classes are composed by mixin with components coming from different packages that separate concerns.
Some basic non-function-changing refactoring begins the process of breaking out runtime1-specific code and separating that from code that will be in common to all runtime backends.
The primary packages in the schema compiler (daffodil-core) are:
dsom - The Daffodil Schema Object Model - object corresponding to the parts of a DFDL schema. Handles properties, property scoping, include/import, namespaces, and all XML-schema-related functionality.
grammar - Introduces combinators and primitives of the data syntax grammar. Supposed to contain all backend/runtime independent logic.
runtime1 - Logic (mixins, methods, members, classes, etc.) specific to the Runtime 1 backend. For example, this includes calculations that create the data structures needed to support streaming unparsing, a complex behavior that other Daffodil runtime backends are unlikely to implement.
Some primary classes and mixins from these packages are shown here:
|
|
The grammar.primitives package has not yet been refactored to break runtime1-specific methods out into runtime1-package mixins. Each Primitive or Combinator should mixin a trait for each runtime. |
|
|
DPath expressions are another whole area that are not as yet refactored to separate specific runtime 1 functionality from general functionality. |
|
|
Eventually this mixin of runtime should be unmixed and converted into a delegation structure so that one can choose a runtime instead of having all runtimes mixed in. E.g., today every runtime has to use different method names. |
In a future version of DFDL we plan to allow recursive definitions. It is theoretically possible to define a recursive structure using only reusable groups:
<xs:element name="r">
<xs:complexType>
<xs:group ref="g"/>
</xs:complexType>
</xs:eleemnt>
<xs:group name="g">
<xs:choice>
<xs:sequence>
<xs:sequence>
<xs:annotation><xs:appinfo source="http://www.ogf.org/dfdl/">
<dfdl:assert testKind="pattern" testPattern="."/><!-- there is more data -->
</xs:appinfo></xs:annotation>
</xs:sequence>
<xs:element name="x" type="xs:string" dfdl:length="1" dfdl:lengthKind="explicit"/>
<xs:group ref="g"/>
</xs:sequence>
<xs:sequence/>
</xs:choice>
<xs:group>
The above example simulates an array using group recursion.
|
|
It is not clear that even if DFDL allows recursion it would allow it on groups alone. Requiring recursion to utilize elements would seem to be consistent with DFDL’s current restriction which requires repeating/optional things to be elements. |
|
|
Furthermore, it is not clear if the above is allowed in XML Schema. XML Schema’s UPA rules may in fact require elements to be used in the formulation of recursive structure. |
Recursion requires evolution of the current Daffodil architecture to one that enables sharing of definitions of groups, elements and types.
This section describes the implementation prior to the fix to Daffodil-2192, and how it evolved. The changes from the prior design were significant.
The code design is somewhat simpler in that prior code has two different kinds of next element resolvers, one for next-siblings, and one for first children of an element of complex type. This is simplified in the current design. There is only one PartialNextElementResolver per TermRuntimeData object.
Note that the prior NextElementResolver class went away and its functionality appears in the PartialNextElementResolver to reflect that the class itself implements only part of the algorithm.
Currently, the InfosetInputter architecture is dependent on being able to take an element name (+ namespace when used), have as a context a current element ElementRuntimeData object, and then given a hash-table which is stored on the element ERD, lookup the name and namespace (when used) to get the next element ERD. This lookup hash table is encapsulated in the NextElementResolver classes. At schema compile time, given each element ERD, it is precomputed what the possible valid set of subsequent following ERDs can be (including the current one again, in case of an array). This set of possibilities is captured in an instance of the NextElementResolver class, and is stored on each ERD.
This process makes unparsing a self-validating kind of processing. As an external representation of the Infoset is converted into an actual stream of Infoset events, each incoming element event is scrutinized against the schema for whether it is allowed. This scrutiny is built into the fact that the incoming element name+namespace is being looked up in the NextElementResolver, and then once each element is created, a new NextElementResolver object is taken from its ERD for the next infoset event lookup.
An invariant (which remains true in current behavior and in proposed new changes) is that the next element resolution process cannot cross a complex -type element boundary, as an end-element event ends the scope of the possible legal subsequent elements that can arrive next. However, within a complex type, there can be many groups and group references.
This architecture depends on the fact that the ElementRuntimeData (ERD) objects are unique per element, and per element context - that is, they are depending on the fact that element ERDs are not shared and so they uniquely identify both the element, and the context of that element (nest of all enclosing groups).
As part of the changes to fix our schema compiler speed/space issues (DAFFODIL-1444), this assumption is no longer valid. Elements (specifically DSOM ElementBase objects) can be shared. Groups can be shared. The expected improvement in schema compiler performance and the space reduction is fundamentally driven from this sharing. This sharing is also needed to implement a desirable future feature which is to enable recursive definitions in DFDL.
Ultimately, the required change is from one where an ERD is a unique identifier of an element and all its dynamic context, to one where because ERDs are shared, the Unparser runtime must maintain a stack of the dynamic context information sufficient to perform next-element resolution as each infoset event must be synthesized.
As part of changes to eventually improve schema compiler space and speed usage, (DAFFODIL-1444) we introduced sharing information to the DSOM objects in the schema.
The sharing information is present - every global schema component object can examine every context in the schema from which it is shared.
This unfortunately creates a situation where we get a combinatorial explosion of computation. The sharable objects, such as a group definition, are still today NOT being shared, they are being copied. Yet within each copy, each element in it behaves as if it was being shared. So, for example, if you ask the last element of a group definition what possible elements can follow it, it responds with a list of every element that can follow for every context where the group is referenced. What’s worse, this same thing is calculated repeatedly since the sharable group is, in fact, not being shared currently so there are many copies of this final element to do this computation on.
The result is something which grows in algorithmic complexity very fast. If you have a very small schema or wait long enough, then compilation of the schema should complete and be correct. Hence, most all small tests work fine. Larger schemas fail to finish compiling in any reasonable amount of time or memory space.